Machine Learning (Part 5): Understanding Reinforcement Learning

Welcome back to our Machine Learning journey! In this part of the series, we'll take a deep dive into reinforcement learning. Just as an explorer navigates uncharted territories, reinforcement learning empowers machines to learn through interaction and decision-making. Let's look at how that process works and also some algorithms related to it.
Before we get into it, if you have missed out on the previous part where we take a deep dive into Unsupervised Learning, click here
What is Reinforcement Learning?
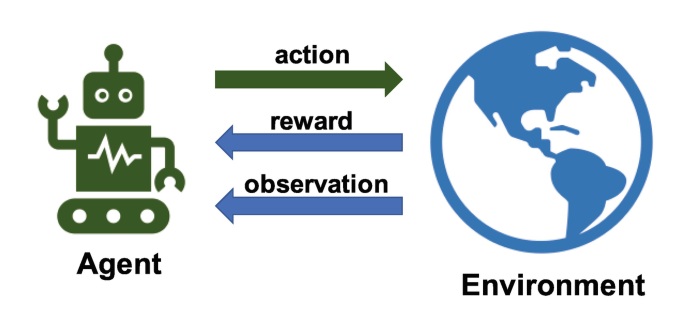
Reinforcement learning is like coaching an athlete to excel in a sport. The machine agent learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. Over time, the agent optimizes its actions to maximize cumulative rewards.

Imagine teaching a dog new tricks using treats as rewards. The dog explores different actions, receives treats for good behavior, and avoids actions that lead to no treats. Similarly, reinforcement learning guides machines to take actions that lead to positive outcomes.
The Process of Reinforcement Learning
Reinforcement learning follows a process that involves interacting with an environment, learning optimal policies, and improving over time.
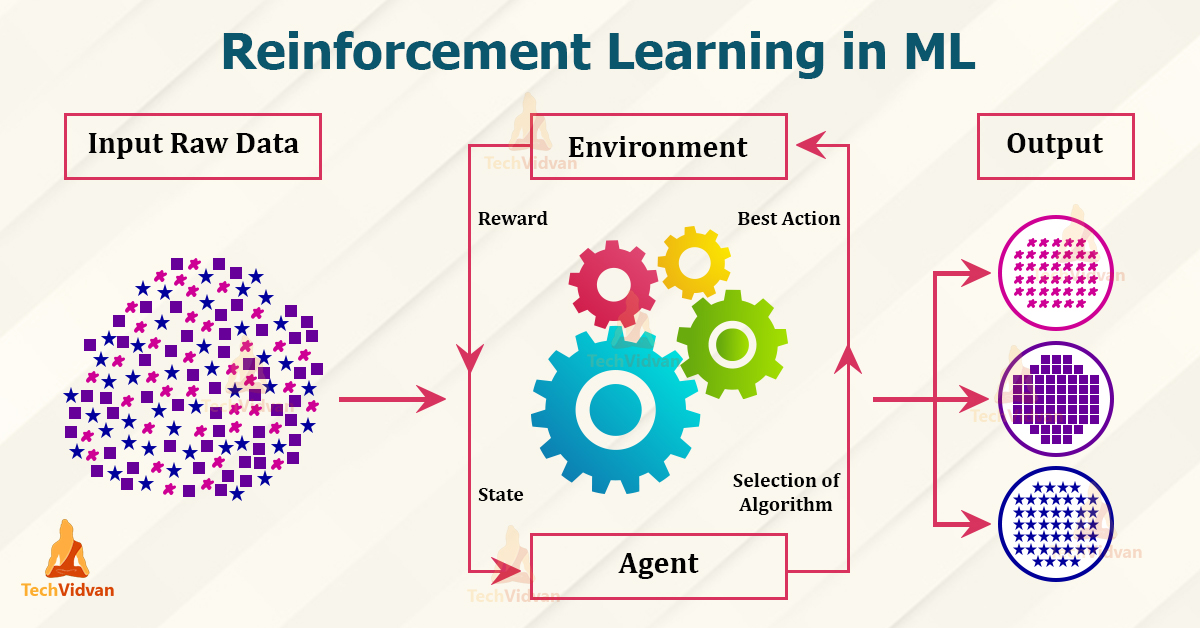
Environment Interaction
The agent interacts with the environment, taking action and receiving feedback in the form of rewards or penalties.
Policy Learning
The agent learns a policy—a strategy that maps states to actions—to maximize cumulative rewards.
Exploration vs. Exploitation
The agent balances exploring new actions (to discover better strategies) and exploiting known actions (to gain rewards).
Learning and Optimization
The agent uses various algorithms to update its policy based on observed rewards and states.
Continuous Improvement
Through repeated interactions, the agent refines its policy to make better decisions.
Common Algorithms in Reinforcement Learning
Q-Learning
Q-Learning is a model-free algorithm that learns optimal action-values for state-action pairs. It's particularly effective for discrete state and action spaces.
In Q-Learning, the agent explores the environment by taking actions and observing the rewards and resulting states. It updates its knowledge of the "Q-values," which represent the expected cumulative rewards for each action in each state. The agent aims to find the best actions in each state to maximize the overall rewards.
How it Works: Q-Learning iteratively updates action-values based on observed rewards and state transitions.
When to Use: Use Q-Learning when the agent interacts with the environment and learns through trial and error.
Example: Teaching a robot to navigate a maze.
Deep Q-Network (DQN)
DQN is an extension of Q-Learning that employs deep neural networks to approximate action-values, enabling it to handle complex state spaces.
The agent uses a neural network to estimate Q-values, which are updated using the Bellman equation. Experience replay stores past experiences, allowing the agent to learn from a variety of states and actions, enhancing its stability and learning speed.
How it Works: DQN uses a neural network to approximate Q-values and experiences replay to enhance learning stability.
When to Use: Use DQN when dealing with high-dimensional state spaces, such as images or continuous data.

Example: Playing Atari games using a DQN agent.
Policy Gradient Methods
Policy gradient methods directly optimize the policy of the agent to maximize expected rewards. They work well in continuous action spaces.
The agent explores the environment, collects rewards, and updates its policy parameters to increase the likelihood of taking actions that lead to higher rewards. By iteratively adjusting the policy, the agent gradually learns the optimal strategy.
How it Works: Policy gradient methods use gradient ascent to update the policy parameters based on the rewards received.
When to Use: Use policy gradient methods when the agent's actions directly influence the rewards received.
Example: Training an agent to perform specific tasks in a simulated environment.
When to Use Reinforcement Learning
Reinforcement learning is ideal when you want to:
Teach machines to make sequential decisions and optimize actions over time.
Deal with environments where feedback is delayed, such as games or robotics.
Train agents to navigate complex, dynamic, or uncertain environments.
Real-time Applications
Game Playing: Training agents to excel in games like chess, Go, or video games.
Robotics: Teaching robots to perform tasks in real-world environments.
Autonomous Driving: Developing self-driving cars that make safe decisions.
Finance: Designing trading strategies that adapt to market dynamics.
Conclusion
As we learned, reinforcement learning empowers machines to learn from their experiences, much like athletes refining their skills over time. Reinforcement learning can handle dynamic and complex scenarios, leading to autonomous learning and decision-making.
One of the disadvantages would be that it requires careful tuning, and long training times, and can suffer from stability and convergence issues.
In the next part, we'll explore semi-supervised learning and its applications. Until then, stay curious and continue your journey into the amazing realm of Machine Learning!




