Machine Learning (Part 12): Navigating Decisions with Decision Trees

Welcome back to our exploration of the vast field of Machine Learning! In this chapter, we'll unravel the intricacies of Decision Trees, powerful models that mimic the decision-making process. Decision Trees are versatile tools applicable to both classification and regression tasks. Let's delve into the theoretical foundations, understand their inner workings, and get hands-on experience by implementing Decision Trees in Python.
Before we get into it, if you have missed out on the previous part where we delved into Logistic Regression, click here.
What are Decision Trees?
Decision Trees are hierarchical structures where each internal node represents a decision based on a feature, each branch represents an outcome of that decision, and each leaf node represents the final prediction or decision. These structures facilitate the modeling of complex decision-making processes.
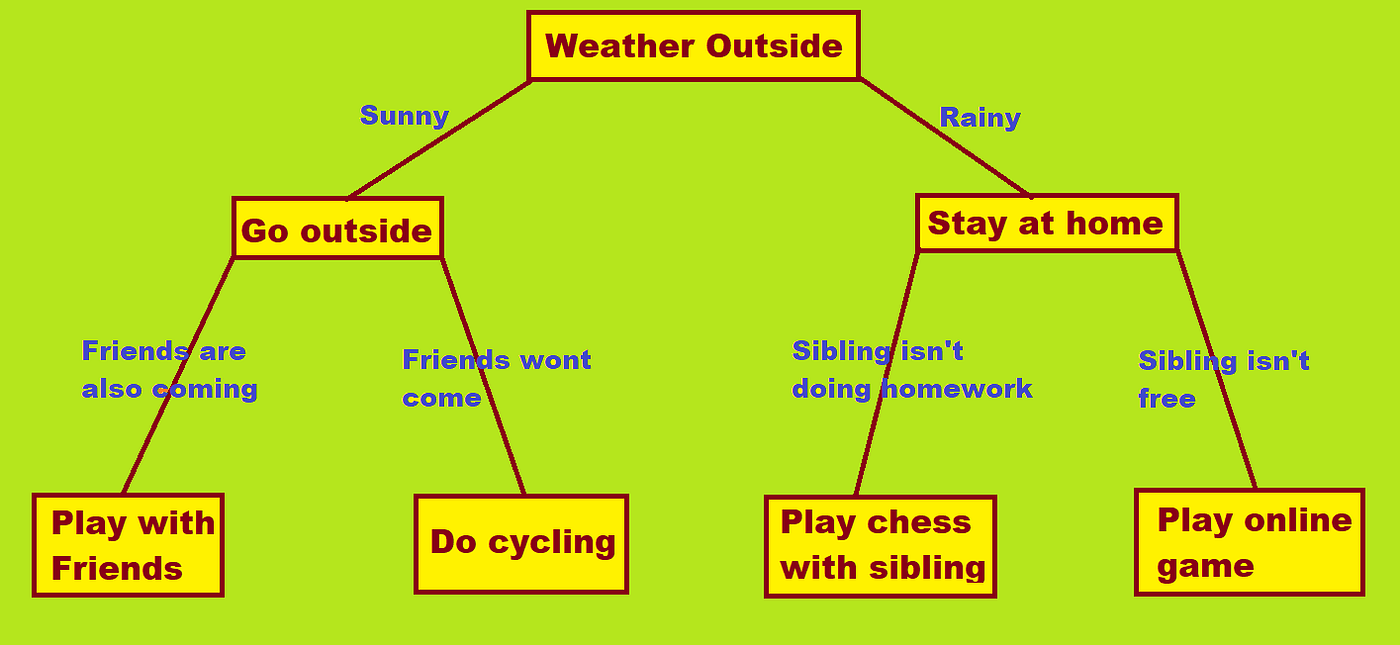
Imagine you're trying to decide whether to play golf. The decision tree might involve questions like "Is the weather good?" If yes, you proceed to another question like "Is it the weekend?" If not, you may ask "Do you have indoor sports equipment?" Each decision and its corresponding branches lead to a final recommendation: either play outdoor sports or find an indoor alternative.
Decision Tree Components
Root Node: The top node that makes the first decision based on a feature.
Internal Nodes: Nodes that follow the root node and make subsequent decisions.
Branches: Paths connecting nodes and representing decisions or outcomes.
Leaf Nodes: Terminal nodes that provide the final decision or prediction.
Let's look at the Decision Tree Process:
1. Entropy and Information Gain
Entropy: A measure of impurity or disorder in a set. Decision Trees aim to reduce entropy.
Information Gain: The reduction in entropy after a dataset is split based on a feature. Decision Trees select features with the highest information gain.
2. Splitting Criteria
Decision Trees use different criteria (like Gini impurity or entropy) to determine the best feature for splitting the dataset at each node.
3. Building the Tree
The tree is built recursively by selecting features that maximize information gain.
The process continues until a stopping criterion is met, such as a predefined tree depth.
Classification in Decision Trees
Classification in Decision Trees involves assigning categories or labels to data points based on their features. Think of it as a hierarchical set of questions that, when answered, lead to the assignment of a specific class to an input.
How it Works:
Decision Nodes: Each internal node poses a question based on a feature.
Branches: The branches represent possible answers or outcomes.
Leaf Nodes: Terminal nodes indicate the assigned class.
When to Use:
Categorical Outcome: Use Classification Trees when the target variable is categorical, such as predicting spam (yes/no) in emails.
Example: Predicting Iris Species
# Load Iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Create and train the Decision Tree model for classification
classification_tree = DecisionTreeClassifier()
classification_tree.fit(X, y)
# Visualize the Decision Tree
plt.figure(figsize=(12, 8))
tree.plot_tree(classification_tree, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
Regression in Decision Trees
Regression in Decision Trees involves predicting a continuous value instead of a category. It's like estimating a numerical outcome based on a series of questions about the input's features.
How it Works
Decision Nodes: Similar to classification, each internal node poses a question based on a feature.
Branches: The branches represent possible answers or outcomes.
Leaf Nodes: Terminal nodes provide the predicted continuous value.
When to Use
Continuous Outcome: Regression Trees are ideal when predicting values on a continuous scale, like house prices based on features.
Example: Predicting House Prices
# Generate example data
np.random.seed(0)
X_reg = 2 * np.random.rand(100, 1)
y_reg = 4 + 3 * X_reg + np.random.randn(100, 1)
# Create and train the Decision Tree model for regression
regression_tree = DecisionTreeRegressor()
regression_tree.fit(X_reg, y_reg)
# Visualize the Decision Tree
plt.figure(figsize=(12, 8))
tree.plot_tree(regression_tree, filled=True)
plt.show()
In these examples, the Classification Tree predicts the iris species, and the Regression Tree estimates house prices. Whether assigning categories or predicting values, Decision Trees offer flexibility across various scenarios.
Full Implementation of Decision Tree Classifier using Python
Let's implement Decision Trees using the Iris dataset. We aim to classify iris flowers into species based on features like sepal length, sepal width, petal length, and petal width.
# Import necessary libraries
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
from sklearn import tree
# Load the Iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the Decision Tree model
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, y_train)
# Make predictions on the test data
y_pred = decision_tree.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
# Visualize the Decision Tree
plt.figure(figsize=(12, 8))
tree.plot_tree(decision_tree, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
# Print model evaluation results
print(f"Accuracy: {accuracy:.2f}")
print("Confusion Matrix:")
print(conf_matrix)
Understanding the Decision Tree Implementation
1. Data Loading and Splitting:
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2. Model Creation and Training:
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, y_train)
3. Making Predictions:
y_pred = decision_tree.predict(X_test)
4. Model Evaluation:
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
5. Visualizing the Decision Tree:
plt.figure(figsize=(12, 8))
tree.plot_tree(decision_tree, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
Outputs:


Try changing the shuffling (random_state) and the test size in the 'train_test_split' function to get an accuracy under 1.
When to Use Decision Trees
Interpretability: Decision Trees are easy to understand and interpret, making them valuable for explaining complex decision-making processes.
Non-linear Relationships: Decision Trees can capture non-linear relationships in the data, providing flexibility in modeling.
Feature Importance: Decision Trees can highlight the importance of different features in the decision-making process.
Ensemble Methods: Decision Trees can be part of ensemble methods like Random Forests, combining multiple trees to enhance predictive performance.
Conclusion
In this chapter, we've journeyed through the theoretical foundations of Decision Trees and implemented them in Python for practical understanding. Decision Trees offer a transparent view of decision-making processes and find applications across various domains. In our next part, we'll explore Random Forests, an ensemble method that builds upon the principles of Decision Trees to improve predictive accuracy. Until then, continue your voyage into the dynamic landscape of Machine Learning!



