Machine Learning (Part 4): Understanding Unsupervised Learning

Welcome back to our Machine Learning journey! In this part of the series, we'll delve into the captivating realm of unsupervised learning. Just like peering into a treasure chest of hidden patterns, unsupervised learning helps us uncover insights and structures within data without any predefined labels. Let's embark on this exploration together!
Before we get into it, if you have missed out on the previous part where we discussed Supervised Learning, click here
What is Unsupervised Learning?
Unsupervised learning is like an adventure without a map—exploring data to find hidden patterns and structures. Unlike supervised learning, here we're not guiding the machine with labeled examples. Instead, we're allowing it to identify similarities, groupings, and trends on its own.

Imagine you're given a collection of various vegetables, and your task is to group them based on their similarities. You don't have labels telling you which vegetable is which; you're relying solely on shared characteristics. Unsupervised learning is akin to this process, where the algorithm clusters similar data points without prior guidance.
What is Clustering?
Clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters**).** Let's look at some clustering methods and other algorithms.
Common Algorithms in Unsupervised Learning
K-Means Clustering
K-Means is used to partition data into distinct groups (clusters) based on similarity. It assigns data points to the nearest cluster center.
How it Works: K-Means initializes cluster centers, assigns data points to clusters, updates cluster centers, and repeats until convergence.
When to Use: Use K-Means when you want to identify natural groupings within your data.
Example: Customer segmentation for marketing strategies.

Hierarchical Clustering
Hierarchical Clustering creates a tree-like structure of nested clusters, where each data point starts as its own cluster and is merged iteratively.
How it Works: Hierarchical Clustering initially treats each data point as a cluster, then iteratively merges clusters based on similarity.
When to Use: Use Hierarchical Clustering to understand the relationships between different levels of clustering.
Example: Organizing species into a taxonomy hierarchy.

Principal Component Analysis (PCA)
PCA reduces the dimensionality of data by transforming it into a new set of uncorrelated variables (principal components).
How it Works: PCA identifies the directions of maximum variance in the data and projects the data onto these components.
When to Use: Use PCA when you want to simplify data while retaining its most important information.
Example: Reducing the number of features in high-dimensional data.

DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN identifies dense regions of data points separated by sparser areas. It's effective at finding clusters of arbitrary shapes.
How it Works: DBSCAN groups data points that are close to each other and marks points in sparser regions as outliers.
When to Use: Use DBSCAN when you want to find clusters of varying shapes and handle noise effectively.
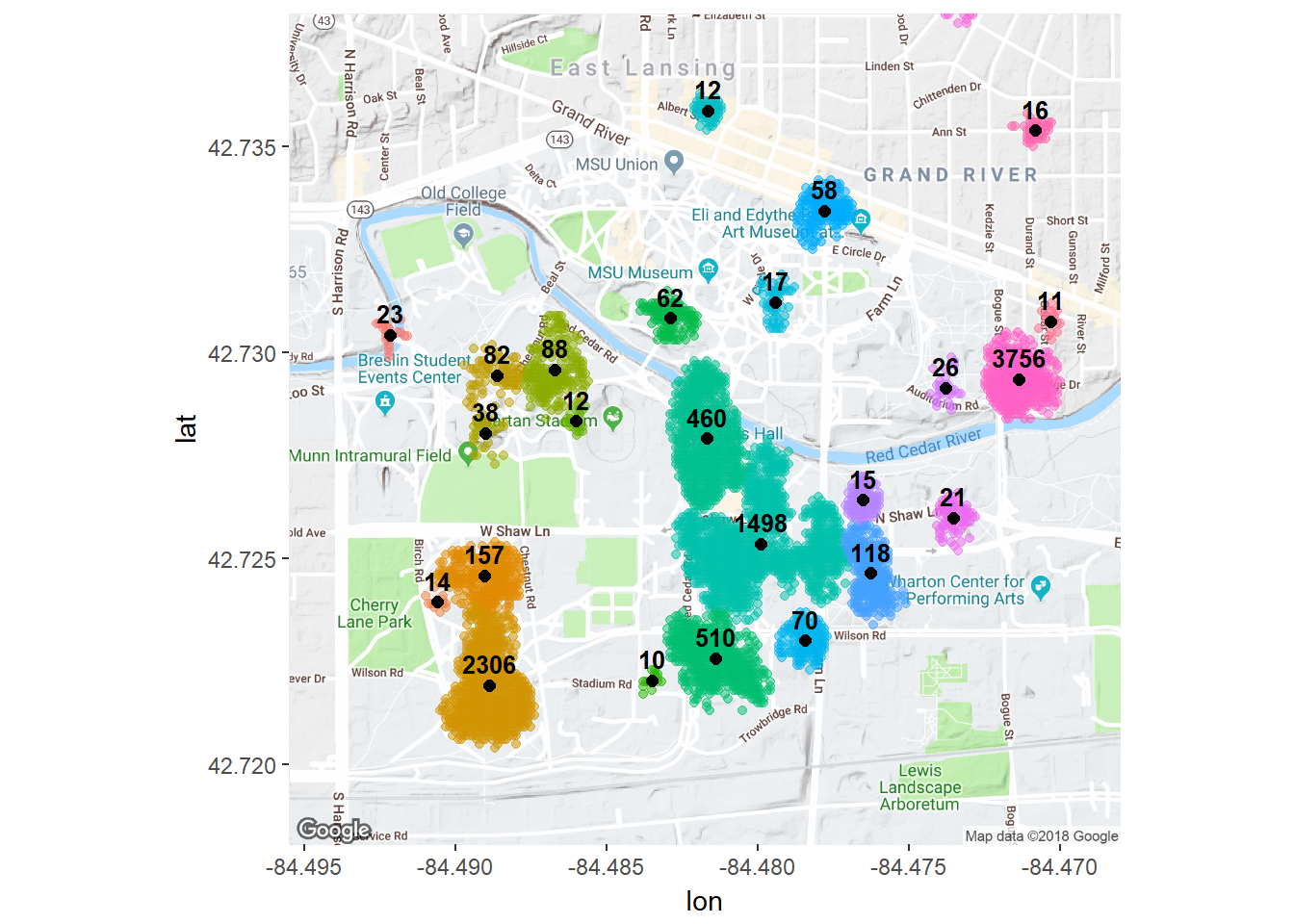
Example: Clustering Google Location History.
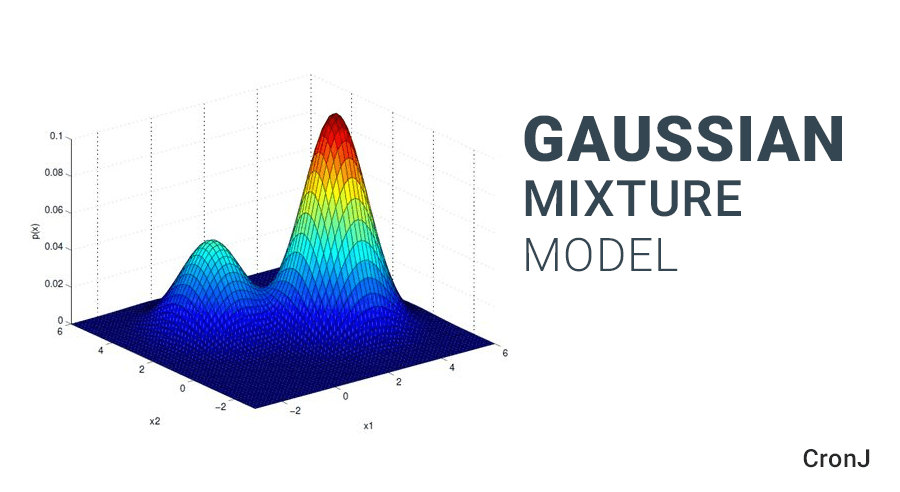
Gaussian Mixture Models (GMM)
GMM assumes that the data is generated from a mixture of several Gaussian distributions. It's more flexible than K-Means and can capture complex data distributions.
How it Works: GMM models data as a combination of Gaussian distributions, estimating their parameters through Expectation-Maximization.
What is Expectation-Maximization (EM)?
EM is an iterative optimization technique used to estimate the parameters of statistical models when some variables are unobserved or missing. In the context of GMM, EM alternates between two steps: the Expectation step (E-step) and the Maximization step (M-step).
Expectation Step (E-step): In this step, for each data point, the algorithm calculates the probability that it belongs to each Gaussian component (cluster), based on the current parameter estimates. This is the "expectation" of the hidden variables, which are the cluster assignments for each data point.
Maximization Step (M-step): In this step, the algorithm updates the parameters of each Gaussian component to maximize the likelihood of the data given the current cluster assignments. This involves adjusting the mean, covariance, and mixing coefficients of the Gaussians to better fit the data.
When to Use: Use GMM when you want to capture clusters with different shapes and handle overlapping distributions.
Example: Anomaly detection in credit card transactions to identify fraudulent activities.
When to Use Unsupervised Learning
Unsupervised learning is ideal when you want to:
Discover underlying patterns or structures in data.
Group similar data points together without predefined labels.
Reduce the dimensionality of high-dimensional data.
Other Applications of Unsupervised Learning include:
Topic Modeling: Extracting themes from large text datasets.
Image Compression: Reducing the size of images while retaining key features.
Conclusion
Unsupervised learning can reveal hidden patterns, requires less manual labeling, and can be applied to various data types. But, Interpreting results may be more challenging, and there's a lack of clear evaluation metrics.
In our next installment, we'll explore a different type of Machine Learning called reinforcement learning, where agents learn to make decisions through interaction. Keep your curiosity alive and continue your journey into the vast world of Machine Learning!




