


Hello again, fellow adventurers! Today, we're going to explore the exciting world of datasets and how they play a vital role in our mission to detect epilepsy using EEG readings and machine learning. But rest easy, because we're going to keep things simple and relatable.
What is a Dataset?
When we talk about datasets in the realm of machine learning (ML), think of them as special collections of information. They're like treasure chests filled with valuable clues and insights. In our case, I've stumbled upon a collection of EEG readings, which are like snapshots of the brain's electrical activity, from many patients. It's as if we've discovered a whole bunch of secret maps that can guide us on our quest to uncover the mysteries of epilepsy.
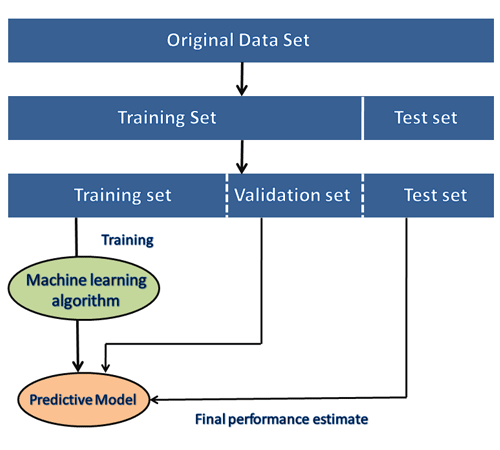
Any dataset once found is usually divided into train and test datasets. The 'train dataset' is used to train the ML model while the 'test dataset' is used for the prediction and performance measurement of the trained model.
Now, here's the exciting part. With this huge collection of EEG data in our hands, we're on the brink of training a smart ML model. But before we dive into that, I'm currently doing some research to figure out which ML model would be the best fit for our mission. It's like deciding which tool from a toolbox would help us crack open the treasure chest and unlock its hidden treasures.
Approach to Choosing the right dataset
As we embark on this data-driven adventure, we need to consider a few important things. First off, we want our dataset to be like a big melting pot, representing a diverse group of people. It's like having a team with different skills and talents, all coming together to tackle the challenge at hand. By including EEG readings from both people with and without epilepsy, we can teach our ML model to spot the unique patterns that might indicate the presence of the disorder.

As we dig into the available datasets, we're careful to choose ones that are reliable and trustworthy. We want clear and consistent recordings, like a smooth sailing journey without any rough waves. We also keep an eye out for any noise or artifacts that might confuse our ML model. It's like checking for any pesky bugs that could spoil our treasure hunt.
Problems that might occur while handling numerical data
Since there's a high possibility that we will be dealing only with numerical data on this project, these are some of the issues/problems we might have to tackle:
Missing Values: Numerical data may have missing values, which can create problems during analysis or model training. Handling missing values requires imputation techniques such as mean, median, or regression imputation.
Outliers: Outliers are extreme values that differ significantly from other data points. Outliers can skew statistical measures and affect model performance. Identifying and appropriately handling outliers is essential to ensure accurate model training.
Scaling and Normalization: Numerical features often have different scales, which can impact the performance of certain ML algorithms. Scaling and normalization techniques like standardization (mean 0, standard deviation 1) or min-max scaling (0 to 1 range) may be necessary to normalize the data and bring features to a comparable scale.
Feature Engineering: Sometimes, the raw numerical data may not provide sufficient predictive power. Feature engineering involves creating new features or transforming existing ones to enhance the performance of ML models. It requires domain knowledge and creativity.
Curse of Dimensionality: When dealing with a high-dimensional numerical dataset, there can be challenges due to the curse of dimensionality. As the number of features increases, the data becomes sparse, and the model may struggle to find meaningful patterns. Feature selection or dimensionality reduction techniques like Principal Component Analysis (PCA) or feature importance analysis can help mitigate this problem.
Multicollinearity: Multicollinearity occurs when two or more features are highly correlated. It can impact model interpretability and cause issues during model training. Addressing multicollinearity involves techniques like feature selection or regularization methods to eliminate or reduce redundant features.
Bias and Skewness: Numerical data may exhibit bias or skewness, affecting the accuracy of ML models. Data transformation techniques like log transformation, power transformation, or Box-Cox transformation can be employed to reduce skewness and make the data more suitable for modeling.
Interpretability and Explanation: Some ML models, especially complex ones, lack interpretability. Interpreting the results and explaining the influence of numerical features on model predictions can be challenging. Simplifying the model or using interpretable models like linear regression or decision trees can help address this issue.
Only after these are dealt with can we start our model training.
Consulting a Neurologist
Finding the perfect dataset isn't a walk in the park. It's more like navigating through a maze of options, trying to discover the hidden gem. Since I don't have the required knowledge to understand these EEG recordings, I'm considering consulting a Neurologist in hopes of getting some insights on these recordings. If we can understand it a little more, then it'd help us in choosing the right dataset. But fear not, because our curiosity, determination, and a sprinkle of wit will guide us on our way.
So, my dear fellow adventurers, let's join forces on this thrilling treasure hunt for the apt dataset. Together, we'll explore exciting possibilities, ignite our imagination, and uncover the secrets of epilepsy detection. Stay tuned for more updates as we come closer to unraveling the mysteries and making a difference!
Disclaimer: Remember, though, that while datasets are essential, our ultimate goal is to provide accurate diagnoses and support for epilepsy. Always consult with medical professionals for proper guidance.
That's it for now, my friends. Until next time, happy hunting, and let's keep the spirit of adventure alive!