


Welcome back to our Machine Learning journey! In this part of the series, we'll dive into supervised learning, a fundamental type of Machine Learning that plays a pivotal role in making predictions and decisions based on labeled data. We'll cover everything from its basics to real-world applications, so let's get started!
Before we get into it, if you have missed out on the previous part where we understood the Machine Learning Process, click here
What is Supervised Learning?
Supervised learning is like having a teacher guide you through learning. In this approach, we provide the machine with labeled training data, where each input has a corresponding correct output. The goal is for the algorithm to learn the mapping between inputs and outputs, allowing it to predict accurate outputs for new, unseen inputs.
Imagine you're teaching a young child to recognize shapes. You show them various images of circles, squares, and triangles, and you label each shape. The child learns the characteristics that differentiate each shape and can then accurately identify new shapes. Supervised learning follows a similar pattern—learning from labeled examples to make predictions.
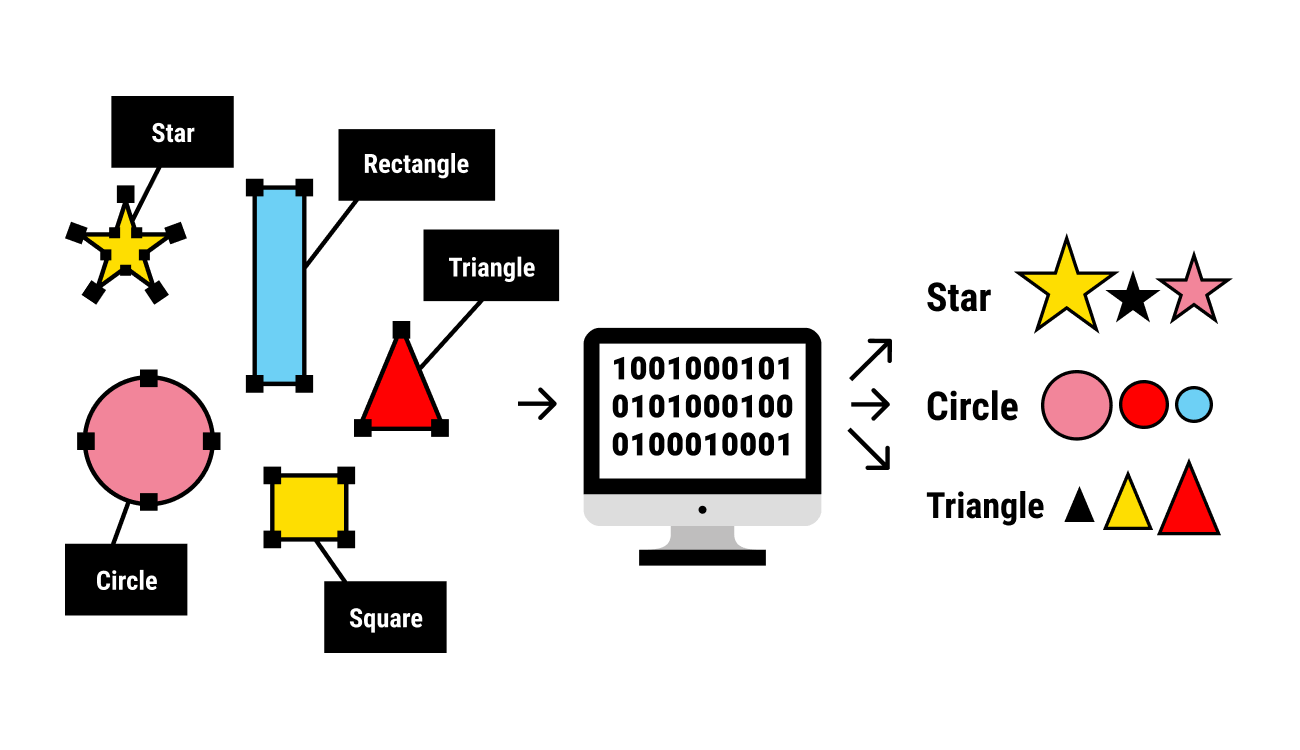
Common Algorithms in Supervised Learning
Supervised learning encompasses various algorithms, each tailored to specific types of problems
Linear Regression
Linear Regression is used when the target variable is continuous and the relationship between the features and the target can be approximated by a linear equation. It fits a straight line to the data points that minimizes the difference between predicted and actual values.
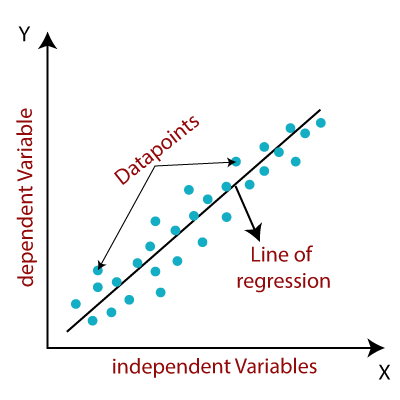
How it Works: Linear Regression finds the slope and intercept of the best-fitting line that minimizes the sum of squared errors between predicted and actual values.
When to Use: Use Linear Regression when you want to predict a continuous numerical value based on one or more input features.
Example: Predicting house prices based on square footage.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
Logistic Regression
Logistic Regression is usually used for binary classification problems, where the goal is to predict one of two possible classes. It models the probability of the input belonging to a particular class using a logistic function.
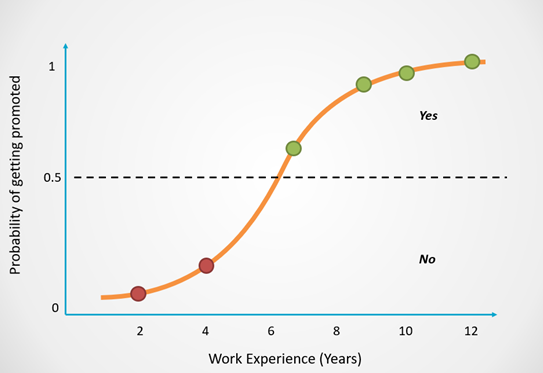
How it Works: Logistic Regression calculates the probability that an input belongs to the positive class using a logistic (sigmoid) function, which maps any input value to a value between 0 and 1.
When to Use: Use Logistic Regression when you want to predict whether an input belongs to one of two classes.
Example: Classifying emails as spam or not spam.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
Decision Trees
Decision Trees are versatile algorithms used for both classification and regression tasks. They create a tree-like structure where each internal node represents a decision based on a feature, and each leaf node represents a predicted output.

How it Works: Decision Trees split the dataset into subsets based on feature values, creating branches that lead to predicted outcomes at leaf nodes.
When to Use: Use Decision Trees when you want to model complex decision boundaries or make predictions based on a combination of features.
Example: Predicting whether a passenger survived or not on the Titanic.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
Random Forest
Random Forest is an ensemble algorithm that combines multiple Decision Trees to improve accuracy and reduce overfitting.
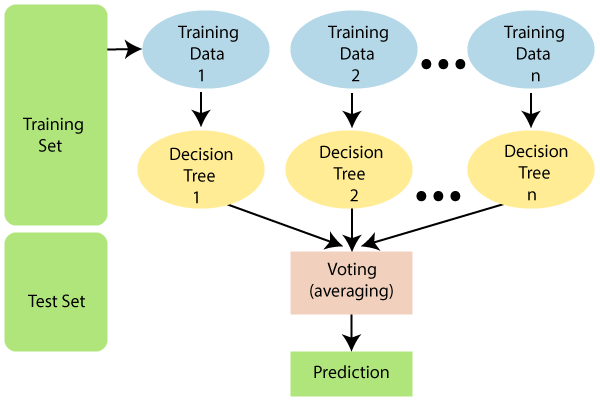
How it Works: Random Forest trains multiple Decision Trees on different subsets of the data and aggregates their predictions to make the final prediction.
When to Use: Use Random Forest when you want to achieve higher accuracy and handle overfitting by combining the strengths of multiple Decision Trees.
Example: Identifying handwritten digits in images.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
When to Use Supervised Learning?
Supervised learning is ideal when you have labeled data and want to make predictions or classify inputs into predefined categories. Use it when:
You have a clear understanding of the relationship between input and output data.
You want to predict numerical values or classify inputs into discrete categories.
You have a sizable labeled dataset available for training.
Real-time Applications
Image Recognition: Classifying images, such as identifying animals or objects.
Medical Diagnosis: Diagnosing diseases based on medical images or patient data.
Text Classification: Categorizing text into topics, sentiments, or spam/non-spam.
Financial Forecasting: Predicting stock prices or credit scores based on historical data.
That's all the basics needed to explore Superwised Learning. In the next part of our series, we'll dive into Unsupervised Learning, exploring its concepts, algorithms, and applications. So, stay curious and keep exploring the exciting vast domain of Machine Learning!