


Table of contents
- Introduction - What is Categorical Data?
- 1. One-Hot Encoding: The Chameleon of Categorical Data!
- Ideal situation for Implementation
- Drawbacks
- 2. Label Encoding: Giving Categories a Numerical Makeover!
- Ideal situation for Implementation
- Drawbacks
- 3. Ordinal Encoding: Bringing Order to the Categorical Chaos!
- Ideal situation for Implementation
- Drawbacks
- 4. Frequency Encoding: Letting Numbers Speak the Truth!
- Ideal situation for Implementation
- Drawbacks
- Conclusion
Introduction - What is Categorical Data?
Greetings, data enthusiasts! Today, we set off on an exciting journey into the realm of categorical data and how to handle it like a pro. But wait, what exactly is categorical data, you ask? Well, in the world of data, information can take various forms. Categorical data is a special type that divides things into distinct groups or categories, much like sorting animals into different species or organizing ice cream flavors into delectable options. That's categorical data! So let's explore different ways to handle them and also the ideal situations to implement them and their drawbacks.
1. One-Hot Encoding: The Chameleon of Categorical Data!
Imagine you have a dataset with a column called "Color" that includes categories like red, blue, and green. One-hot encoding comes to the rescue! It transforms each category into a separate column, and if an observation belongs to a particular category, it gets a 1 in that column and 0 in the rest. It's like giving each color its spotlight on the dance floor, so they can show off their uniqueness!
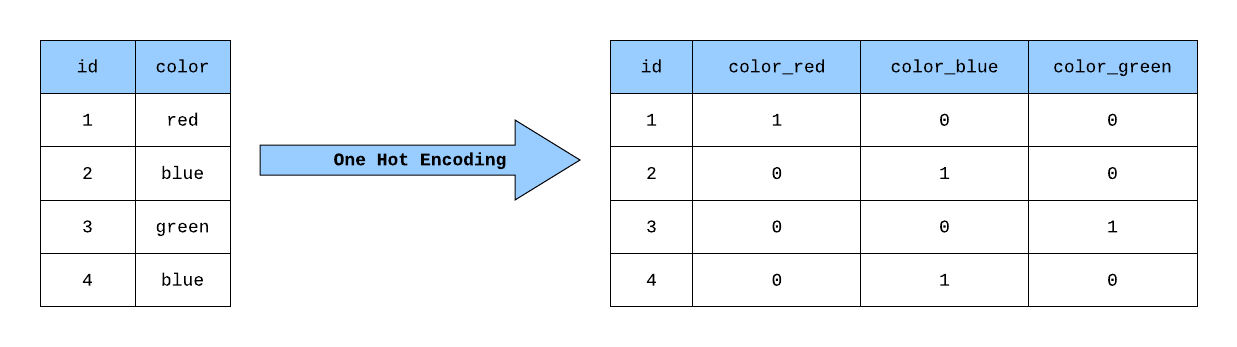
Ideal situation for Implementation
One-hot encoding works wonders when the categories don't have any inherent order or relationship. It's perfect for variables like types of animals, car models, or ice cream flavors, etc.
Drawbacks
One potential drawback of one-hot encoding is that it can lead to high-dimensional data if there are many unique categories. This can increase the complexity of the dataset and may require additional computational resources.
2. Label Encoding: Giving Categories a Numerical Makeover!
Let's say you have a dataset with a column called "Size" that includes categories like small, medium, and large. Label encoding can help us here! It assigns a unique numerical value to each category. For example, small could be 0, medium could be 1, and large could be 2. It's like giving each category a secret code number, so they can participate in numerical calculations without losing their identity!

Ideal situation for Implementation
Label encoding is handy when the categories have a natural order or hierarchy. For instance, clothing sizes (XS, S, M, L) or education levels (primary, secondary, tertiary) can be encoded numerically to capture their inherent order.
Drawbacks
One potential drawback of label encoding is that it introduces an arbitrary numerical order to the categories, which may mislead the model into assuming a natural order or relationship where none exists. This can lead to incorrect interpretations of the data.
3. Ordinal Encoding: Bringing Order to the Categorical Chaos!
Imagine a dataset with a column called "Rating" that includes categories like poor, fair, good, and excellent. Ordinal encoding saves the day! It assigns a numerical value to each category based on its rank or position. In our example, poor could be 1, fair could be 2, good could be 3, and excellent could be 4. It's like giving each category a spot on the podium, reflecting their level of awesomeness!
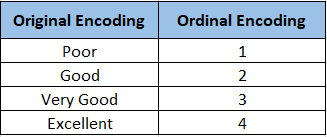
Ideal situation for Implementation
Ordinal encoding is ideal when the categories have an ordered relationship, like customer satisfaction ratings or academic performance levels. It captures the essence of their ranking, ensuring that the analysis doesn't miss out on their importance.
Drawbacks
One potential drawback of ordinal encoding is that it assumes an equal distance between the categories, which may not always hold in reality. This can introduce bias in the analysis and affect the accuracy of the results.
4. Frequency Encoding: Letting Numbers Speak the Truth!
Picture a dataset with a column called "City" that includes categories like New York, London, and Paris. Frequency encoding comes to the rescue! It replaces each category with its frequency or occurrence in the dataset. So, if New York appears 50 times, it gets encoded as 50, and so on. It's like giving each city a popularity score based on its presence in the dataset!




Ideal situation for Implementation
Frequency encoding works well when the frequency of occurrence of a category provides valuable information. It can be used in cases like customer locations or product sales data, where the frequency itself carries meaning.
Drawbacks
One potential drawback of frequency encoding is that it can amplify the importance of rare categories if they have a high frequency in the dataset. This can lead to overfitting and biased results.
Conclusion
Congratulations, my fellow data adventurers! You've journeyed through the whimsical world of categorical data and explored various ways to handle them. Remember, each method has its strengths and weaknesses. By understanding the drawbacks, you can make informed decisions on which approach to choose for your data analysis. So, embrace the quirks and unique qualities of your data, and select the method that best suits your situation. Just like characters in a fantastical tale, each categorical variable has its role to play in unraveling the mysteries hidden within the data. So, let the magic of categorical data unfold, and may your analytical adventures be filled with insights and fun!